


[10:14 Tue,11.October 2022 by Thomas Richter] |
After the generation of arbitrary images and videos by means of a simple text description, now comes another logical development step - the generation of arbitrary 3D models. The new method developed by Google and christened "DreamFusion" is also based on a pre-trained 2D text-image diffusion model (such as Google&s Imagen or Stable Diffusion) and generates 3D objects after description, which can be viewed from any angle, re-lit by any illumination or integrated into any 3D environment. DreamFusion can not only generate any simple object, but it can also perform an action and combine it with another object (such as "a ghost eating a hamburger") or, for example, wearing a certain clothing ("a chimpanzee dressed like Henry VIII, King of England"). As with the image generation AIs, multiple results can be generated using a prompt - moreover, the algorithm can easily be extended to generate multiple 3D models simultaneously. There is already an official  DreamFusion The chance to create so easily complex 3D-models of arbitrary objects will open or simplify many application possibilities. The next logical step is then the simple animation of these models or even the specific modification. 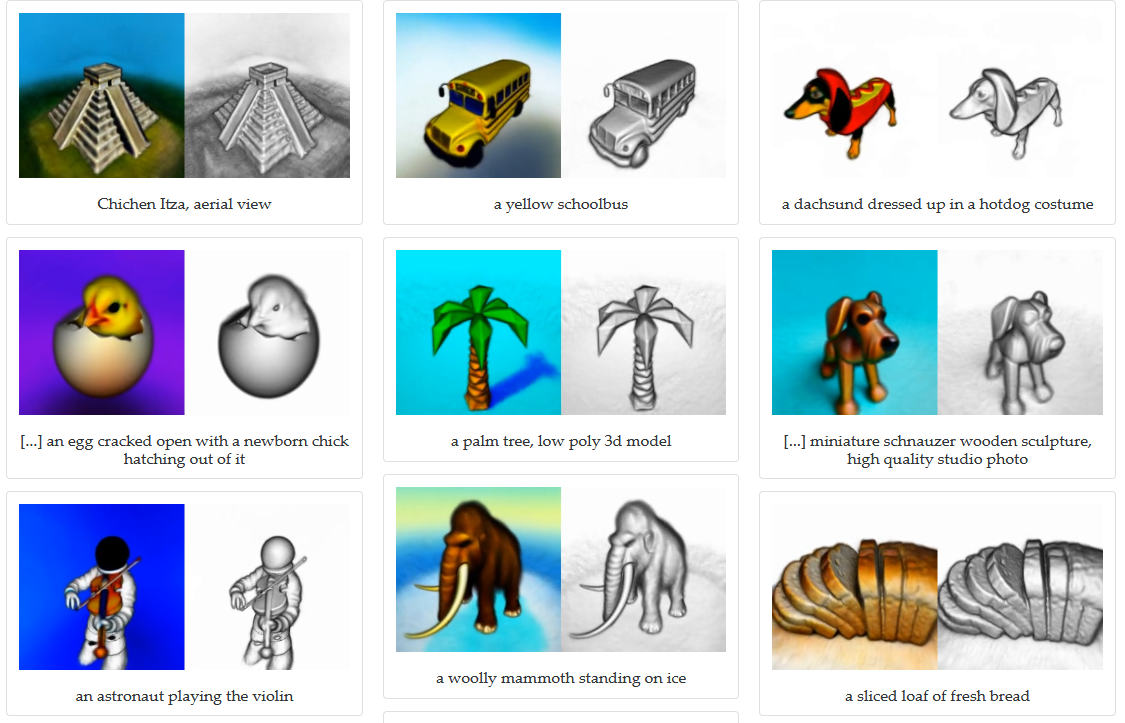 DreamFusion Unfortunately, Google has not published the code for DreamFusion or provided public access to the model with the possibility for users to generate 3D models themselves, but developers have already started to implement the idea behind DreamFusion via stable diffusion as an open project called deutsche Version dieser Seite: DreamFusion: Neue Google KI generiert beliebige 3D Modelle - nur per Textbeschreibung |
|
|