OpenAI, the creators of GPT-3, the largest neural language model to date, have scored another AI coup: DALL-E can generate images from plain text, but with an unprecedented level of detail.
What at first sounds like a cheap magic trick shows on closer inspection simply incredible capabilities. The long published blog allows you to play with numerous parameters and then marvel at the generated images.
According to rumors, a completely free text input is not planned for the sole reason (yet??) to exclude a primarily pornographic use for the time being. Other models, such as Deep Fakes, were first used in the mud corner, as is well known.
But enough of words. Take a look at one of the thousands of examples that can be generated in the linked article. For example, we have designed DALL-E watches, which are supposed to remind us of Pokemon Pikachu:
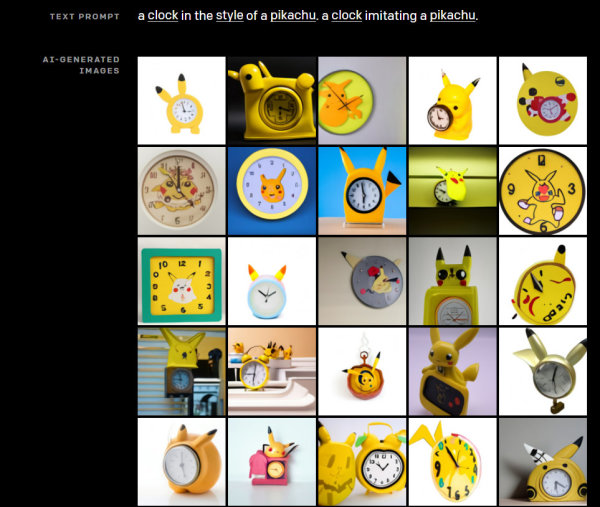
Mind you, none of the clocks shown here exist in reality. All are random inventions of DALL-E, which has simply "seen" a million other watches and tries to imagine how a "Pikachu watch" could probably look like.
If you play around with the website for a while, you quickly get the feeling that the step to moving images isn't too big either. And if you look at the speed at which these Ki models have developed over the last 5 years, it will probably be well before the next decade.
DALL-E once again confirms our assumption that artificial intelligence is going to turn the film industry upside down. Filmmaking as we know it today (apart from documentary films) will perhaps function completely differently in 20 years...



;)