It sounds like another milestone in the current rapid development of artificial intelligence. Nvidia's latest online AI app, GauGan2, can create photo-realistic images based on a textual description of a scene.
For example, you tell the network "beach with sunset in front of blue parasols" and after a short wait, the server delivers an image that most likely plausibly represents the same situation.
For inexperienced users, this might seem almost magical, especially if you combine this function with a voice input. In our eyes, it is nevertheless only a relatively small leap compared to earlier versions of the software. After all, "only" areas in the latent space were linked with additional verbally definable terms here, which has already worked in AI research for quite some time.
The space of possible results is also strongly limited by scenarios that the network has learned. In turn, it remains interesting that one can subsequently intervene in a generated image with the familiar tools. Thus a forest or mountains can be extended or "limited" very simply with the appropriate brushes.
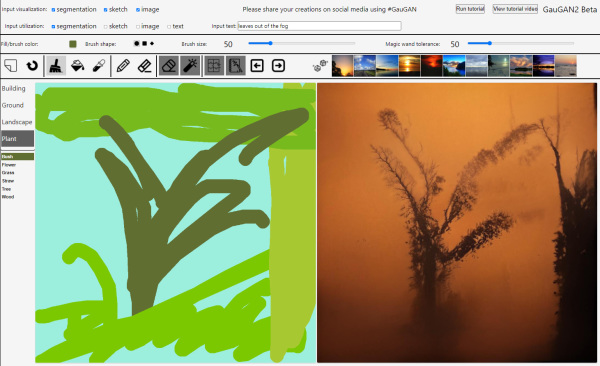
It is not yet possible with GauGan2 to create virtual scenarios for one's own film by simply issuing a command in the computer. But the program already shows that with extended sample size and more learning resources such ideas will soon come into the realm of possibility.
It will probably become interesting at some point when GANs can visually convert complete novels into feature films. And as a director, you mainly change minor details in the adaptation with correction brushes. That will probably still take a few decades, though. But the creation of virtual, photorealistic scenes via speech is likely to be seen before the end of this decade.
If you don't want to fantasize, but just want to play around with the possibilities of GauGan2 right now, you can do so  here.
here.



;)