

[16:09 Mon,20.September 2021 by Thomas Richter] |
The method can be used for various purposes: of course it is perfect for remixing music if you do not have the individual tracks of the original recording - in the case of vocal recordings in videos, the voices could theoretically be dubbed in another language afterwards. It would be interesting to try whether the algorithm is also able to extract voices from recordings in front of a background noise - it could then be used like an intelligent noise filter to produce clearer recordings afterwards. As always, the Those who do not have the necessary knowledge can try out the algorithm deutsche Version dieser Seite: KI trennt Musik in separate Gesangs- und Begleitmusik-Tonspuren |
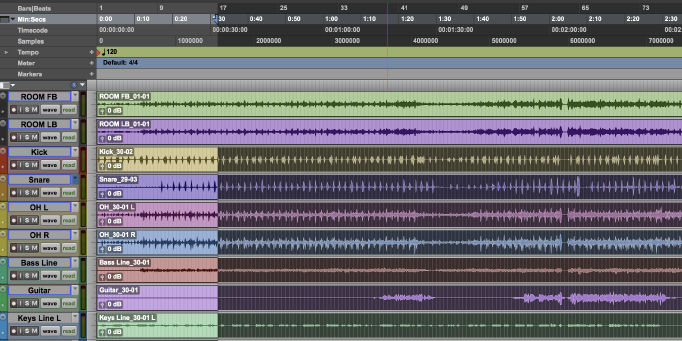
 A team from the AI Lab at ByteDance, the parent company of TikTok, has unveiled a new neural network-based method for separating music recordings into multiple individual audio tracks. The following example demonstrates quite nicely what the new algorithm is capable of: it can quite cleanly separate the vocal track from the musical accompaniment, or even the drums or bass - and the music without the bass and drums.
A team from the AI Lab at ByteDance, the parent company of TikTok, has unveiled a new neural network-based method for separating music recordings into multiple individual audio tracks. The following example demonstrates quite nicely what the new algorithm is capable of: it can quite cleanly separate the vocal track from the musical accompaniment, or even the drums or bass - and the music without the bass and drums. |
|