Although we see new research advances in diffusion-based video generation almost weekly, a fundamental problem exists here: the existing diffusion models only allow for relatively short models, since the image content cannot (yet?) be generated consistently over longer periods of time.
A new project called DynVideo-E tries to solve this problem with a quite analytical approach for a special case: The input video is always a moving human being followed by a moving handheld camera.
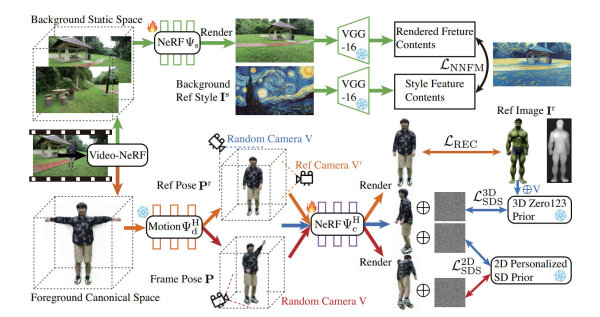
DynVideo-E replaces human and background separately
By using dynamic NeRFs (Neural Radiance Fields), we try to first understand the whole shot as a textured 3D space obtained from the viewpoints of the moving camera. The person appearing in the original video is thereby reduced to the movement of his poses.
This subsequently allows the background to be replaced separately and the person in the video to be reshaped. This can happen, for example, by simple prompting. Sounds of course again a bit bumpy and difficult to imagine? So here again the video to the paper, which presents many descriptive examples to DynVideo-E:
Even if the results are still far from being photorealistic, the project demonstrates the possibility in principle of specifically modifying individual objects in a video. Last but not least, it is also conceivable to subsequently use DynVideo e-clips as input for another diffusion-based model, which could then "render" even more photorealistically.
That AI models can create impressive images should be indisputable by now. DynVideo-E, on the other hand, shows a possible idea of how AI models in general could also be controlled more reliably. After all, the area of precise control over the image is likely to be in particularly high demand for research in the near future.



;)