


[16:10 Wed,8.March 2023 by Thomas Richter] |
A team of researchers from Nvidia and the University of Tübingen has presented a new (old) method for generating images via AI, which has two major advantages over the previously used method. The new method, christened StyleGAN-T, is based quite classically on GANs (Generative Adversarial Network), which has long been used by Nvidia in the form of
;) This method, thanks to the new research, can now also generate images by prompt, much like current image AIs, such as DALL-E2, Midjourney, or the open source and therefore most widely used Stable Diffusion. These all rely on the latent diffusion model to generate images from text. In contrast, the new StyleGAN-T method, which has been christened StyleGAN-T, has two particular positive features: it is significantly faster and can morph better between the results of different prompts. How fast StyleGAN-T is (and how well it can switch from almost smoothly one image to another) is well demonstrated by the following video, in which each 512 x 512 pixel frame was generated in 0.1 seconds - i.e. almost in real time - on a The difference in the speed of image generation also becomes clear in the following overview, a comparison with other image AIs such as 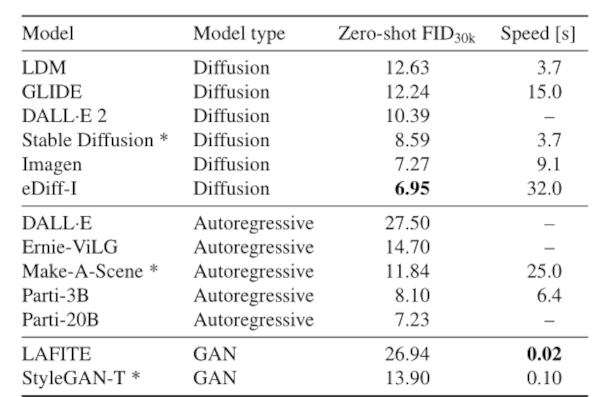 On weaker GPUs than the highly specialized Nvidisa NVIDIA A100, image generation runs slower than 0.1 seconds per image, of course, but the relative speed compared to images generated by diffusion should remain about the same. The second advantage of generating images via GANs is their typical ability to explore latent space, i.e., interpolate between different results and thus visually morph between different results at the same or even different text prompts to make them blend seamlessly. This general capability of (image) GANs is demonstrated quite nicely in the following clip from 2 Minute Paper: Bild zur Newsmeldung:
deutsche Version dieser Seite: Neue Nvidia-KI generiert Bilder 30x schneller als Stable Diffusion |
;)
|
|